Cyprus University of Technology
Christos Christodoulou, Nikos Salamanos, Pantelitsa Leonidou, Michail Papadakis, Michael Sirivianos
https://arxiv.org/abs/2307.12155
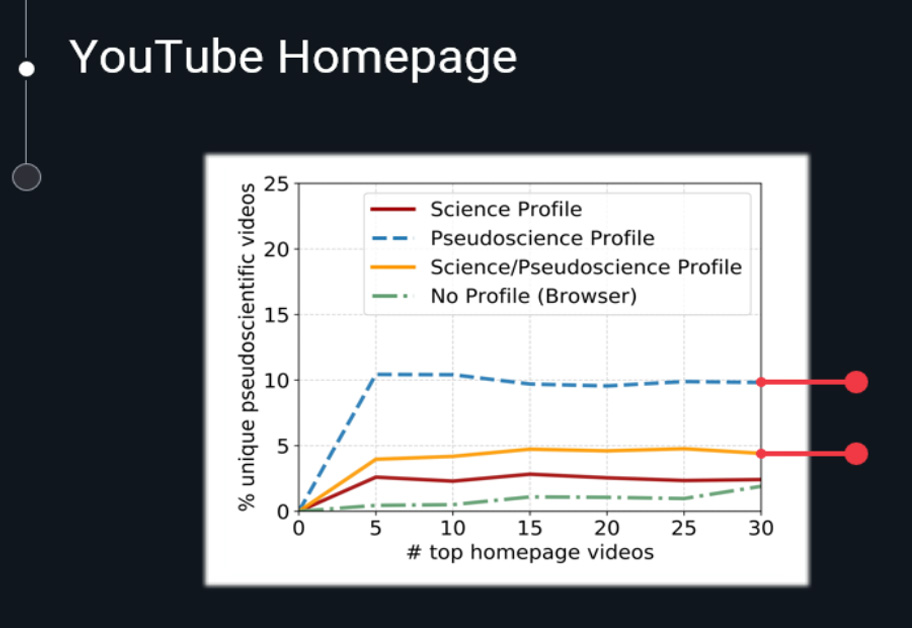
YouTube, as a dominant platform for video content, has become an essential source of information for many. However, its user-generated nature makes it susceptible to the spread of misinformation. The challenge intensifies when considering the platform’s recommendation algorithms, which might inadvertently amplify misleading content. The implications of such misinformation can be severe, especially when it concerns topics of public health and safety.
In our research titled “Identifying Misinformation on YouTube through Transcript Contextual Analysis with Transformer Models”, we embarked on a journey to detect and categorize misinformation on YouTube using advanced machine learning techniques. We gathered datasets encompassing YouTube videos related to vaccine misinformation, pseudoscience, and a collection of fake news articles. These datasets were then annotated based on their veracity, distinguishing between valid information and misinformation.
Utilizing transformer models such as BERT, RoBERTa, and ELECTRA, we fine-tuned these models for our specific task. Additionally, we explored the potential of few-shot learning, a technique that allows models to make accurate predictions with limited examples. This was particularly beneficial given the vast and diverse nature of content on YouTube.
Our findings were illuminating. For instance, in the dataset related to vaccine misinformation, the RoBERTa model achieved an impressive accuracy of over 94%. Interestingly, when it came to pseudoscientific content, few-shot learning models outperformed the fine-tuned ones, highlighting their potential in contexts with limited training data.
Our study underscores the potential of advanced machine learning techniques in identifying and countering misinformation on platforms like YouTube. It emphasizes the need for continuous efforts in this domain, given the ever-evolving nature of content on such platforms.
The following figures show the evaluation of the fine-tuning base transformers model and few-shot learning on the three datasets.
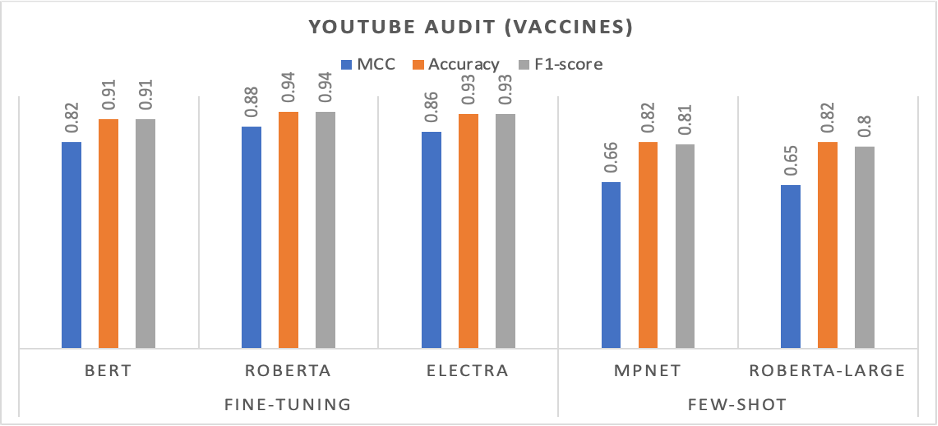
Evaluation of the fine-tuning base transformers model and few-shot learning on the YouTube Audit (vaccines) dataset
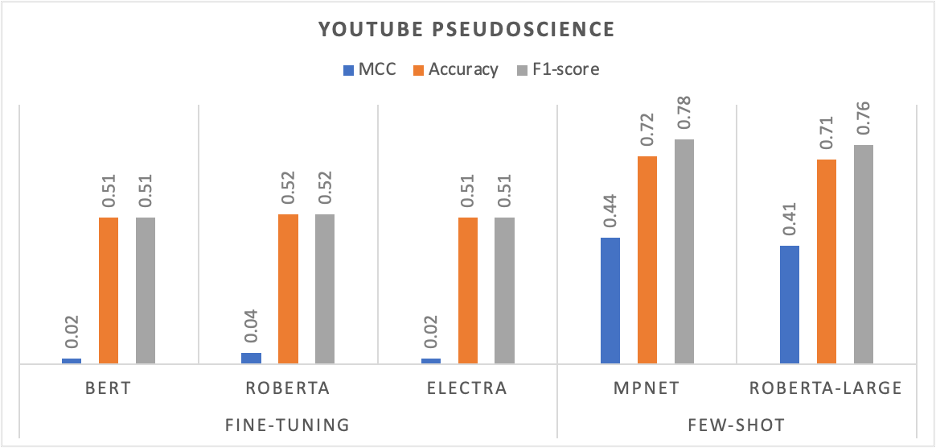
Evaluation of the fine-tuning base transformers model and few-shot learning on the YouTube Pseudoscience dataset.
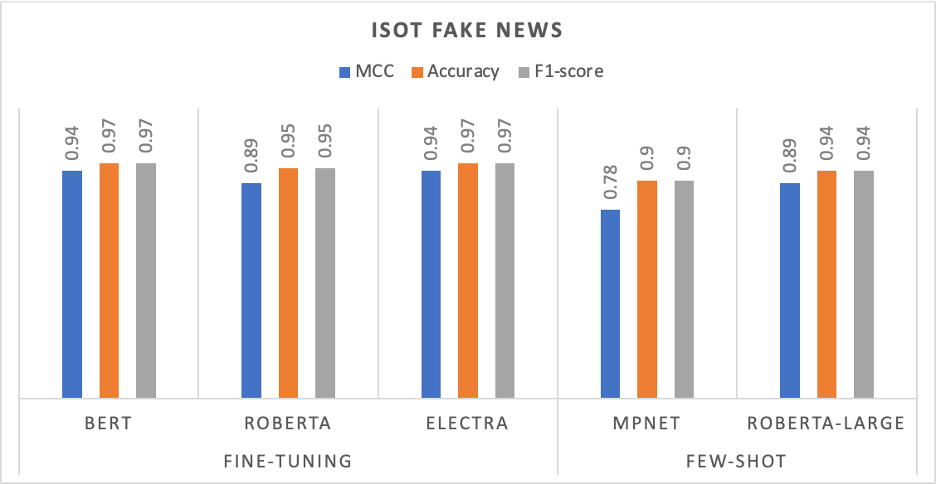
Evaluation of the fine-tuning base transformers model and few-shot learning on the ISOT Fake News dataset.
Funding from:
MedDMO