One of the core functionalities of the provided platform is the automatic visual analysis of every asset at the time it is uploaded and its annotation with descriptive text and tags so that it can be easily retrieved and filtered. By applying annotations as filters in asset search and retrieval, users can easily find content in large-scale collections that fits their needs and organise it in semantically coherent groups (the Projects). For the asset annotation process, several models have been integrated to provide information ranging from objects and actions recognized in assets, to descriptive text captions that provide a user-friendly description of the assets. In more details, the automatic multimedia analysis and annotation process employed for each asset includes the following:
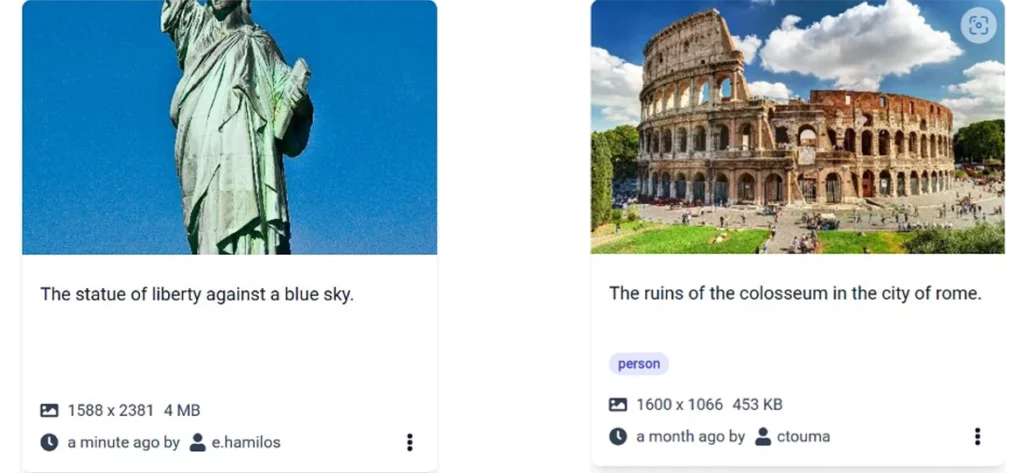
Automatic image captioning: Captioning can greatly enhance image retrieval by generating a free-text description for each image, providing additional context for the visual content. The following Figure shows two asset cards with the corresponding generated captions. By indexing these captions, we are able to retrieve assets even if the user has not provided any relevant metadata or textual description. For example, a user can retrieve the assets shown in the figure, depicting the Statue of Liberty and the ruins of colosseum, with corresponding queries, even though the uploader provided no such information.
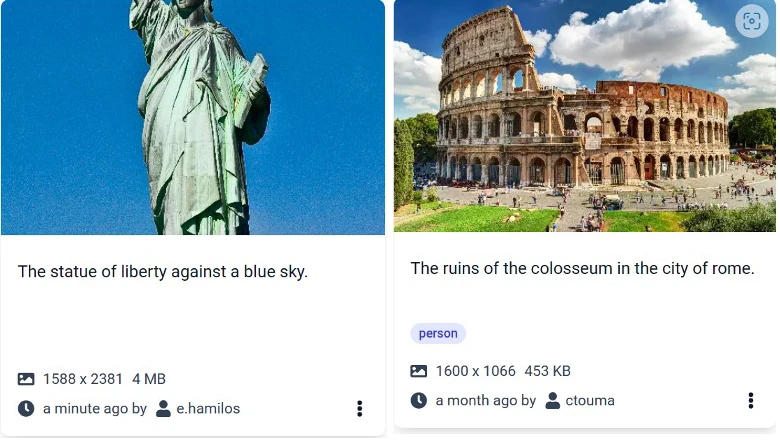
Two asset cards with automatically generated captions
Object detection: The object detection model is used to identify objects within images and video frames. In the case of images, we detect and store the bounding box containing the corresponding object, while in videos we also provide temporal information. If a user wants to find images or videos containing a specific object, they can filter assets by using the objects filter and the platform will return all images and videos that have been annotated with that label. The following figure shows three asset cards, two images and one video with the corresponding identified objects.

Search and retrieve with the ‘object filter’ – examples
Action recognition: The action recognition model is used to identify actions within images and video frames. Action recognition in images and videos indicates another category that a user could use to filter multimedia content. If a user wants to find images and/or videos containing a specific action, they can filter assets by using the action filter and the platform will return all images and/or videos that have been annotated with that label. In the following figure, we provide three examples, two videos, and one image with the corresponding recognized actions.
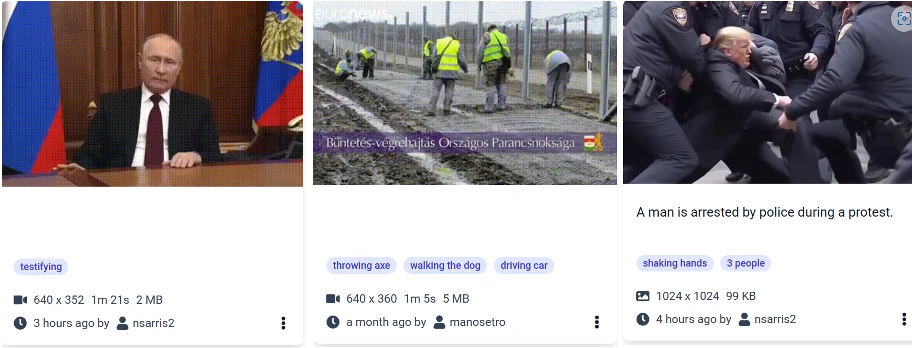
Search and retrieve with the ‘action filter’ – examples
Content Moderation: In the platform two moderation models are employed to filter content, ensuring the platform remains safe and appropriate for all users. We trained two moderation models that are able to detect disturbing and Not Safe for Work (NSFW) content. For images, the moderation results, including a confidence score, are stored and indexed. For videos, the models are applied to key-frames, and a video is considered NSFW or disturbing if at least one scene receives such a tag. At retrieval time, users have the option to include or exclude that type of content, while the UI uses these tags to blur the corresponding assets to prevent user exposure to potentially inappropriate content. For example, at the left of the following figure, the user has enabled the Disturbing filter to get only those that have been tagged as such. Users can choose to reveal the actual content at their own discretion by clicking the reveal button at the upper right corner of each asset, as it is depicted at the right of the figure.
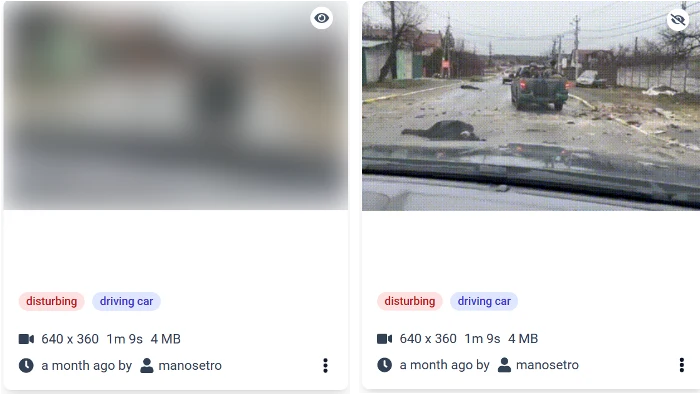
Figure 4: Asset with disturbing content – blur or reveal the actual content
Meme Detection: For images, we apply a meme detection model to each image to determine whether it is a meme or not. The result is stored and indexed. The following figure presents one image that has been categorised as a meme in the MedDMO workspace.
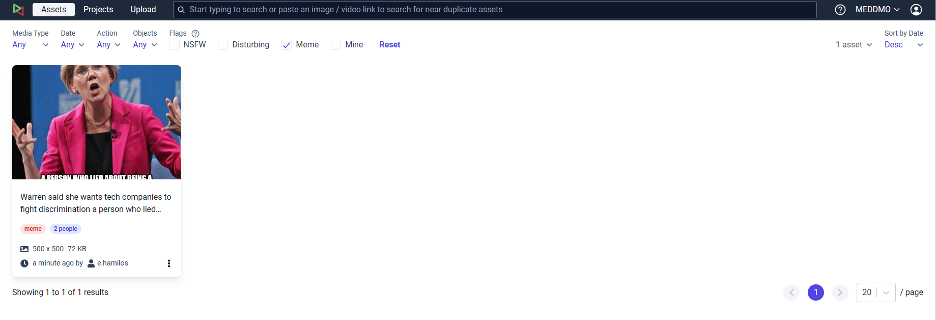
Figure 4: Asset with disturbing content – blur or reveal the actual content
Furthermore, the automatic multimedia analysis creates for each asset a table of properties, an asset description, and a metadata analysis table. The user can see the general properties in the asset details tab that appears when clicking an asset as illustrated in the following figure, while, when clicking on the Metadata tab the user can browse through the complete image metadata as shown below. The user can edit the description of an asset by clicking the edit button and providing a new asset description as depicted below.

Asset details tab – Properties
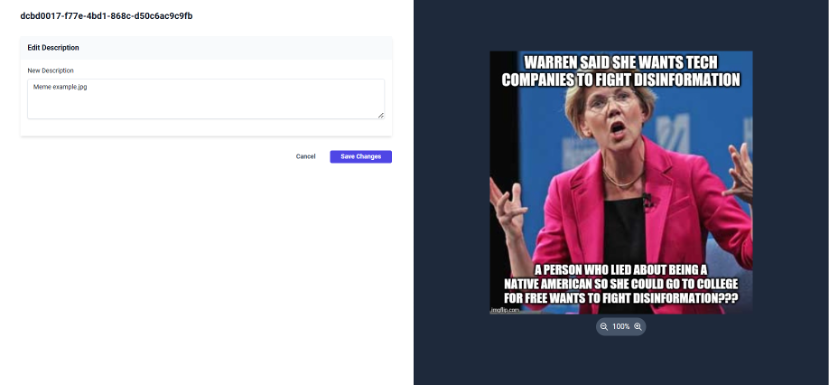
Editing the asset description
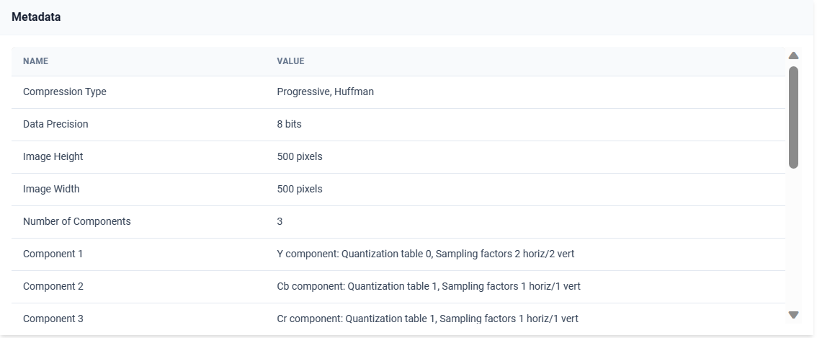
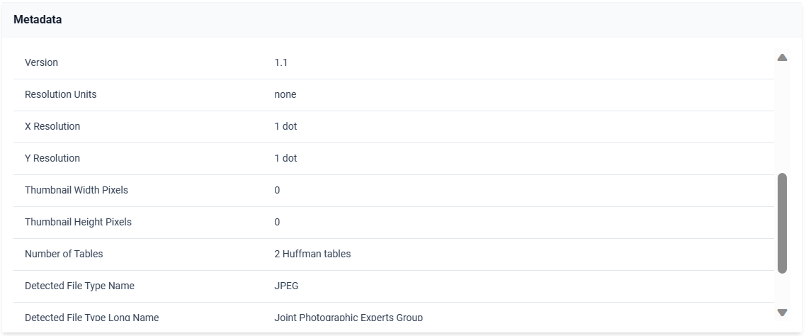

Metadata analysis table